

Business intelligence is more than a buzzword. Data can now be crunched in thousands of novel ways, helping us make better predictions and more informed business decisions.
But data doesn’t always tell the whole story, and it’s important to understand the limitations, especially when it comes to ZIP codes. In the article "How ZIP Codes Nearly Masked the Lead Problem in Flint" Richard Casey Sadler, a geographer and assistant professor at Michigan State University, outlines how a ZIP code analysis prolonged a major health crisis.
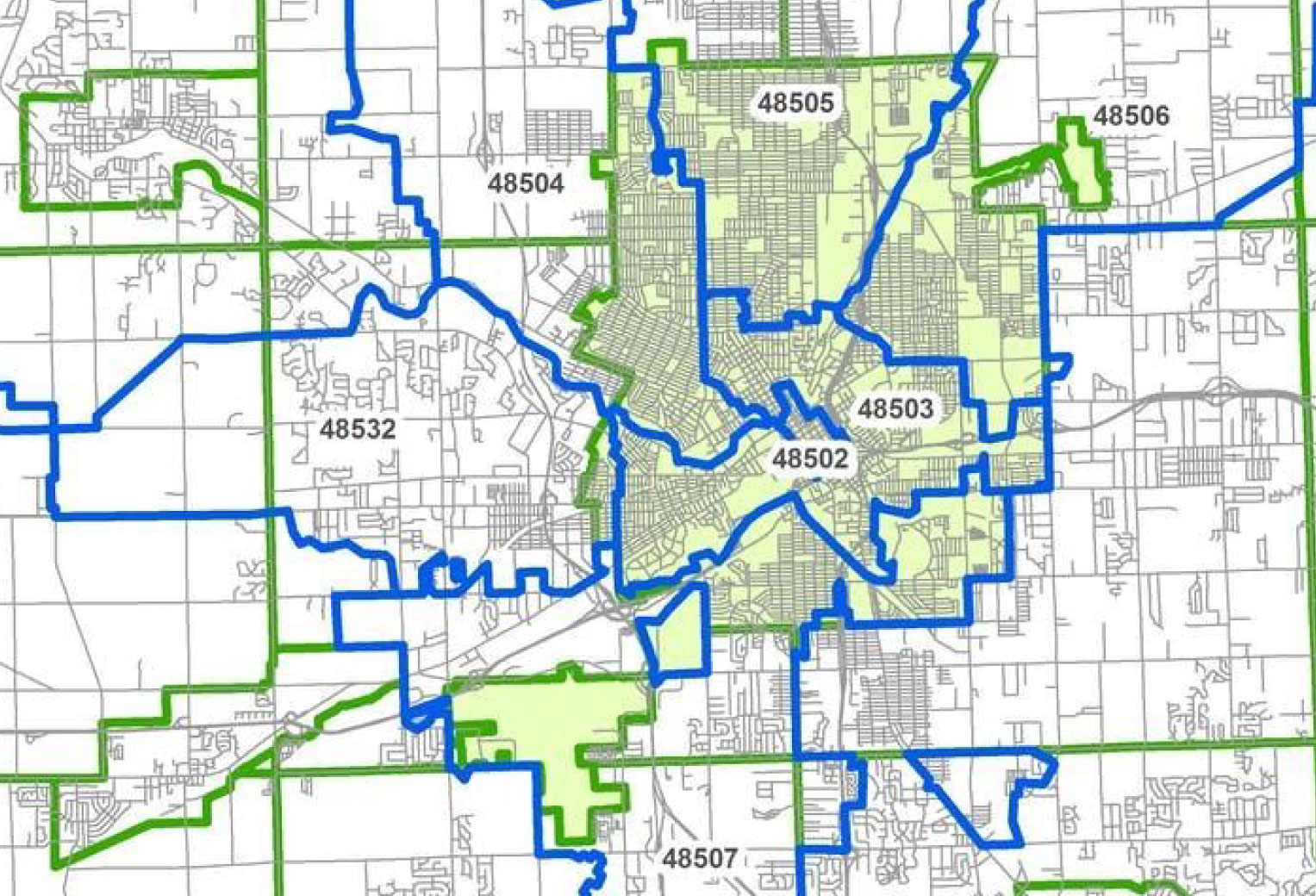
In attempting to measure the impact of lead-contaminated water, researchers inspected blood lead levels in children with Flint ZIP codes. The problem was that one-third of homes with a Flint ZIP code were located outside the city, and did not use the Flint water system. Children in these homes, presumably with normal blood lead levels, were erroneously included in the analysis, diluting the statistical impact of the data.
As you can see in the map below, ZIP code analysis failed to adequately capture the scope of the lead problem in Flint. Sandler says relying on ZIP codes “reflects a fundamental ignorance of geography.” The Flint case underscores the shortcomings of ZIP code data, and the need to understand its benefits and challenges.
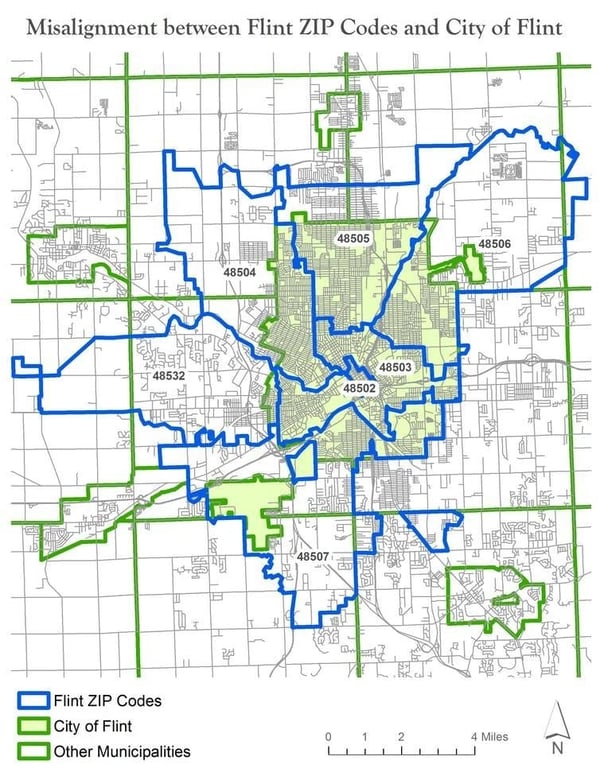 Using ZIP codes to analyze data can mask important trends.
Using ZIP codes to analyze data can mask important trends.
Related:
How WSRB Determines the Protection Class for Each Property
How are ZIP codes defined and determined?
Unlike other geographic data, ZIP codes are an invented concept - and a recent one at that. Before the early 1960s, ZIP codes didn’t exist. But as our population grew, the U.S. Postal Service (USPS) realized it needed a more efficient way to handle the growing volume of mail. It rolled out the mandatory five-digit ZIP Code system in 1963 (ZIP standing for Zone Improvement Plan) for mail sorting and to improve first-class mail delivery.
The ZIP code database contains address ranges for delivery points along city streets, single points for post office boxes in rural communities, and specific locations that get a large volume of mail. Though many maps display ZIP codes as polygons, USPS does not publish or use ZIP Codes in this way. USPS also has the right to change a ZIP code or create new ones as they see fit.
ZIP codes are assigned to a city based on the location of the post office that receives and sorts the mail for all addresses within that ZIP code. The ZIP code indicates the city where the mail is initially routed, not necessarily where it ends up.
In the Flint example, the Flint city post office also processes mail for eight different municipalities surrounding it. When more than one incorporated city shares a ZIP Code, USPS assigns primary and secondary cities.
The Census Bureau uses both city and ZIP Codes in their data. This is important to know, because the Census directly provides a lot of business data, and even more data is sourced using Census figures (e.g. the American Community Survey and U.S. Bureau of Labor Statistics).
Each decade, as part of the 100% U.S. population count, the Census creates the ZIP Code Tabulation Area (ZTCA). Using it, they compile population and housing data by ZIP code, as well as by city, county, and state. Once established, the ZTCA does not change until the next census.
 Every region of the United States has a unique Zip Code assigned to it.
Every region of the United States has a unique Zip Code assigned to it.
Related:
To Get the Right Data, Start in the Right Place: ZIP Code Accuracy
How does WSRB use ZIP code information?
At WSRB, we strive to include the most accurate address data and have incorporated it into a ZIP code polygon layer. Each month, our GIS staff import address data from cities and counties, and refine the layer using USPS data and other sources.
When you turn on the parcel layer, you can see how we’ve matched the ZIP layer to parcels, and not drawn a line down the center of a street. For the rest of the country, we use the Census Bureau’s ZIP Code layer, which lets you zoom to any location in the U.S. using the ZIP Code search function. Our data is so current that government entities use it as a resource.
ZIP code data can be useful but proceed with care.






